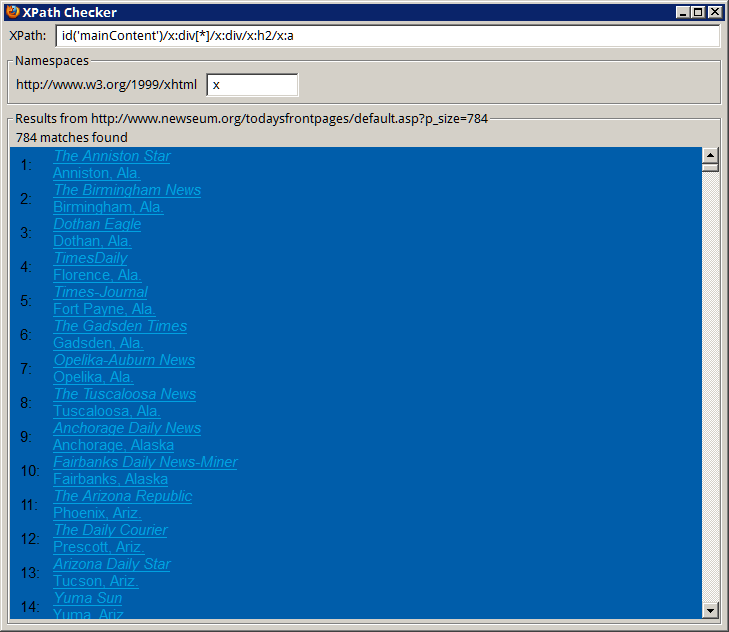
A seção “Capas de Hoje” do Newseum é uma grande fonte de pesquisa para professores, estudantes e jornalistas. Mas, quando a gente precisa de todas as capas para algum estudo comparativo, é chato ficar clicando em cada miniatura e depois em cada link para PDF ou jpeg. Neste artigo, mostro como esta tarefa pode ser facilitada com um pouco de processamento de texto básico.
A jogada é obter uma lista com os nomes dos arquivos de capas e, a partir dela, gerar uma lista com os links para os arquivos PDF (ou jpg).
Colheita de soja. Foto: Wenderson Araujo/Trilux Fotógrafos de mídias rurais já perderam a conta das…
João Batista MezzomoAuditor fiscal O que está por trás de tudo o que está acontecendo…
A.k.a. "SexyCyborg". A mulher do século 21. Naomi Wu testa seu iluminador de implantes na…
A principal ferramenta do jornalista de dados é a planilha, tipo LibreOffice Calc, M.S. Excel…
Rita Almeida, 9 de março de 2019 Psicóloga Rita Almeida: não delirantes, mas deliroides. Não…
Rafael Azzi5 de outubro de 2018 Você se pergunta como um candidato com tão poucas…
{kind=link}