Há tempos estou pensando sobre um sistema editorial que auxilie a produção de jornais pequenos, usando um CMS para gerar conteúdo a ser editado e diagramado. Mas eu estava pensando em soluções muito complicadas, imaginando uma interface com banco de dados e outras misturas exotéricas. Na verdade, tudo pode ser relativamente fácil graças aos padrões. Especificamente, graças ao padrão XML-RPC. E à API implementada em blogs, como a do WordPress.
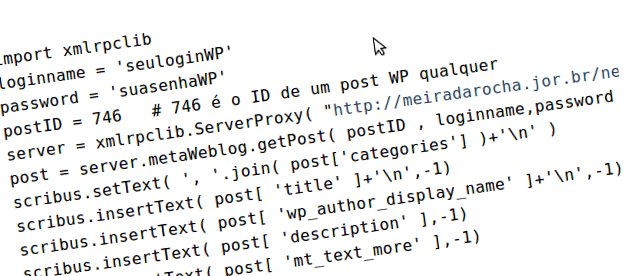
Com estes padrões, basta usar o módulo Python xmlrpclib para recuperar as informações de um post a partir de seu número ID. Como no trecho de código abaixo, que busca num blog WordPress o título de um post, o nome do autor, o sumário e o restante do post, e insere tudo num quadro de texto previamente selecionado:
import xmlrpclib loginname = 'seuloginWP' password = 'suasenhaWP' postID = 746 # 746 é o ID de um post WP qualquer server = xmlrpclib.ServerProxy( "http://meiradarocha.jor.br/news/xmlrpc.php" ) post = server.metaWeblog.getPost( postID , loginname,password ) scribus.setText( ', '.join( post['categories'] )+'\n' ) scribus.insertText( post[ 'title' ]+'\n',-1) scribus.insertText( post[ 'wp_author_display_name' ]+'\n',-1) scribus.insertText( post[ 'description' ],-1) scribus.insertText( post[ 'mt_text_more' ],-1)
Agora, o trabalho de criar um sistema editorial fica muito mais fácil. Para facilitar ainda mais, escrevi o script abaixo que importa não só o texto de um post, formatando negritos e itálicos (graças à dica de Aurélio A. Heckert para usar o módulo Python HTMLParser), mas também importa todas as imagens com legenda que encontrar, dentro da marcação “caption” do WordPress. A legenda da imagem fica como legenda, mesmo, e o título da imagem é importado como crédito da foto.
Depois de importar o texto e as imagens (que ficam empilhadas no canto inferior direito da página), pode-se diagramar a matéria com ajuda dos scripts que montam matérias e fotos, encontrados em outros artigos neste site.
Falta fazer uma melhor interpretação de tags HTML, como criação de listas numeradas e com bolinhas, citações etc. Mas o Scripter do Scribus vai mudar na próxima versão 1.5. Então, não vale a pena investir nesta versão do script.
Baixe o script, tire a terminação “.txt” e coloque “.py” (o WordPress não permite upload de programas como scripts Python, por segurança). Edite a variável wp_site para apontar ao seu site antes de usar: Revista Diagrama Post (2010-01-25a)
Embora o conteúdo textual seja importado, pode haver problemas de formatação de itálicos e negritos e aplicação de estilos de parágrafos. Por deficiências do próprio Scribus (que é um programa jovem e ainda tem deficiência de design) e de meu próprio algoritmo, os estilos de parágrafos são aplicados apenas nos títulos mas estes trechos não são formatados conforme o estilo aplicado. Bug do Scribus. Já o corpo do texto fica no formato de parágrafo default mas sem estilo aplicado. O usuário deve aplicar os estilos de parágrafo pelo editor de texto interno do Scribus (pela barra de ferramentas, não pela coluna de estilos à esquerda do texto, para não apagar os itálicos e negritos). Também deve, provavelmente, limpar a formatação dos títulos pela aba “Text” da paleta de controle do programa (tecla F2).
As fotos importadas devem ser desagrupadas e resselecionadas pela ordem foto-legenda-crédito antes de se aplicar o script de redimensionar fotos. Outro bug do Scribus.
Esta técnica também pode ser aplicada ao Blogger. Aqui está um exemplo de como acessar posts do Blogger:
# http://code.google.com/intl/pt-BR/apis/blogger/docs/1.0/developers_guide_python.html
import gdata
import atom
from gdata import service
blogger_service = service.GDataService('joseantoniorocha@gmail.com', 'xxxxxxxx')
blogger_service.source = 'exampleCo-exampleApp-1.0'
blogger_service.service = 'blogger'
blogger_service.account_type = 'GOOGLE'
blogger_service.server = 'www.blogger.com'
blogger_service.ProgrammaticLogin()
def PrintUserBlogTitles(blogger_service):
query = service.Query()
query.feed = '/feeds/default/blogs'
feed = blogger_service.Get(query.ToUri())
print feed.title.text
for entry in feed.entry:
print "\t" + entry.title.text
def getBlogId():
query = service.Query()
query.feed = '/feeds/default/blogs'
feed = blogger_service.Get(query.ToUri())
blog_id = feed.entry[0].GetSelfLink().href.split("/")[-1]
def PrintAllPosts(blogger_service, blog_id):
feed = blogger_service.GetFeed('/feeds/' + blog_id + '/posts/default')
print feed.title.text
for entry in feed.entry:
print "\t" + entry.title.text
print "\t" + entry.content.text
print "\t" + entry.updated.text
print
def PrintPostsInDateRange(blogger_service, blog_id, start_time='2009-01-01', end_time='2010-01-13'):
query = service.Query()
query.feed = '/feeds/' + blog_id + '/posts/default'
query.published_min = start_time
query.published_max = end_time
feed = blogger_service.Get(query.ToUri())
print feed.title.text + " posts between " + start_time + " and " + end_time
for entry in feed.entry:
print "\t" + entry.title.text
print "\t" + entry.content.text
print "\t" + entry.updated.text
print
Para quem quer uma ferramenta mais “profissional”, pode tentar o Blurb Booksmart, software que cria um livro inteiro a partir de um blog.
Colheita de soja. Foto: Wenderson Araujo/Trilux Fotógrafos de mídias rurais já perderam a conta das…
João Batista MezzomoAuditor fiscal O que está por trás de tudo o que está acontecendo…
A.k.a. "SexyCyborg". A mulher do século 21. Naomi Wu testa seu iluminador de implantes na…
A principal ferramenta do jornalista de dados é a planilha, tipo LibreOffice Calc, M.S. Excel…
Rita Almeida, 9 de março de 2019 Psicóloga Rita Almeida: não delirantes, mas deliroides. Não…
Rafael Azzi5 de outubro de 2018 Você se pergunta como um candidato com tão poucas…
{kind=link}